Claude Code 是怎么管理上下文的:四层压缩策略源码精读
做 agent 的人迟早都会撞上同一堵墙:上下文越聊越长,最后塞不进模型了。
最朴素的做法是写一个压缩函数:到了阈值就让模型把历史总结一下,用摘要替换原对话。听起来很合理,但真做出来你就会发现一堆坑:
- 压缩本身也要消耗 token,压到一半
prompt_too_long怎么办? - 压缩完模型”忘了”用户最近想干什么。
- 每次都调 API 做摘要,成本和延迟都很高。
- 旧的工具结果(一大坨文件内容、命令输出)其实占了大头,但没必要让模型重写摘要。
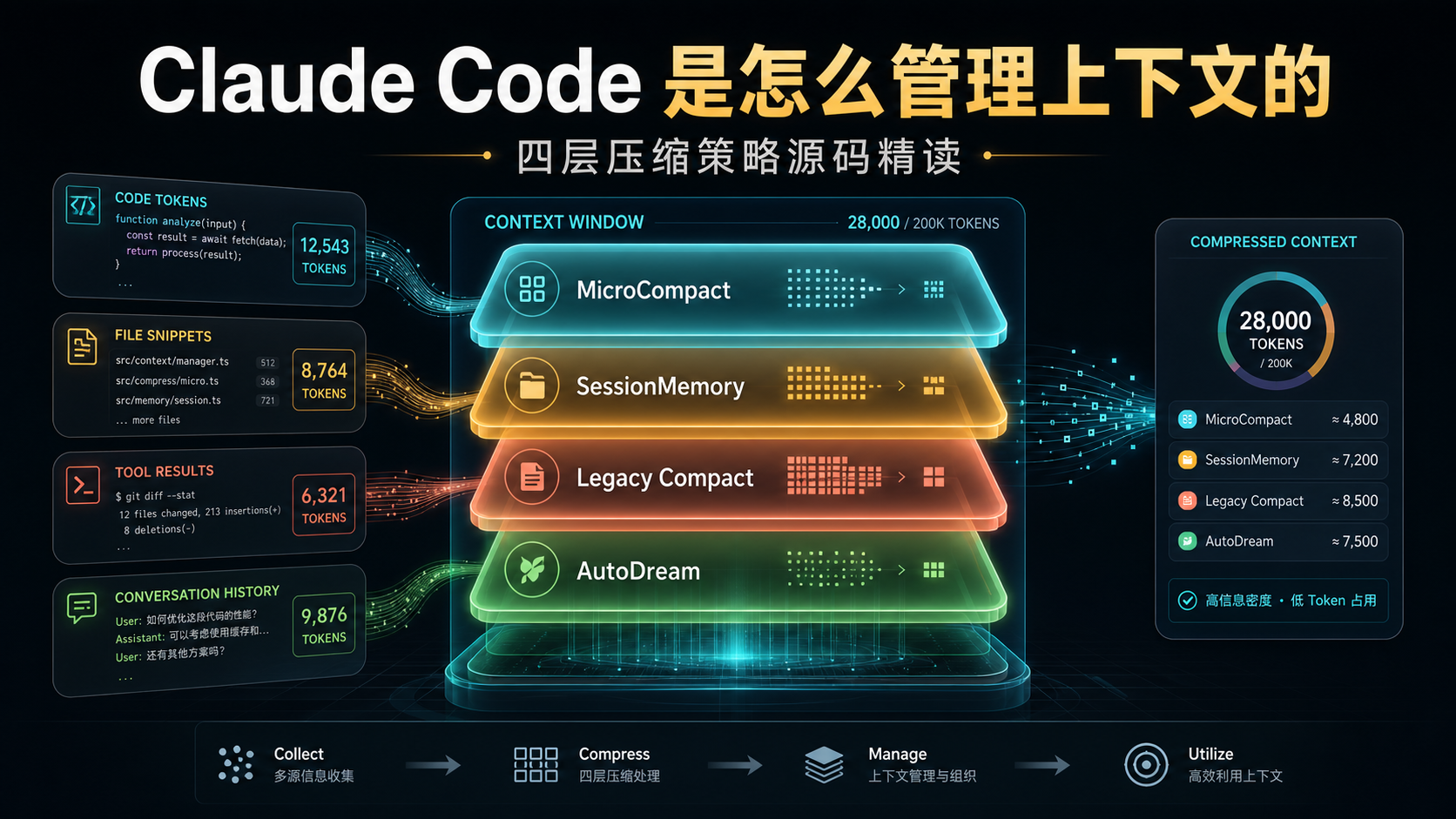
Claude Code 的源码(src/services/compact/ 和 src/services/SessionMemory/)给了一套相当成熟的答案。它不是”一个压缩函数”,而是 四层叠加的策略。
读完这篇你就知道每一层在解决什么问题,以及哪些设计可以直接抄到自己的 agent 里。
一、先看全景:四层是怎么分工的
| 层 | 时机 | 调 API | 阻塞主循环 | 干什么 |
|---|---|---|---|---|
| MicroCompact | 后台、按时间衰减 | 否 | 否 | 清理旧的 tool_result |
| SessionMemory Compact | 接近阈值时优先尝试 | 否 | 是 | 读已抽好的摘要文件 |
| Legacy Compact | SessionMemory 失败时 fallback | 是(1 次) | 是 | 让模型生成结构化摘要 |
| ExtractMemories / AutoDream | 每轮后台 / 24h+ | forked agent | 否 | 跨会话沉淀知识 |
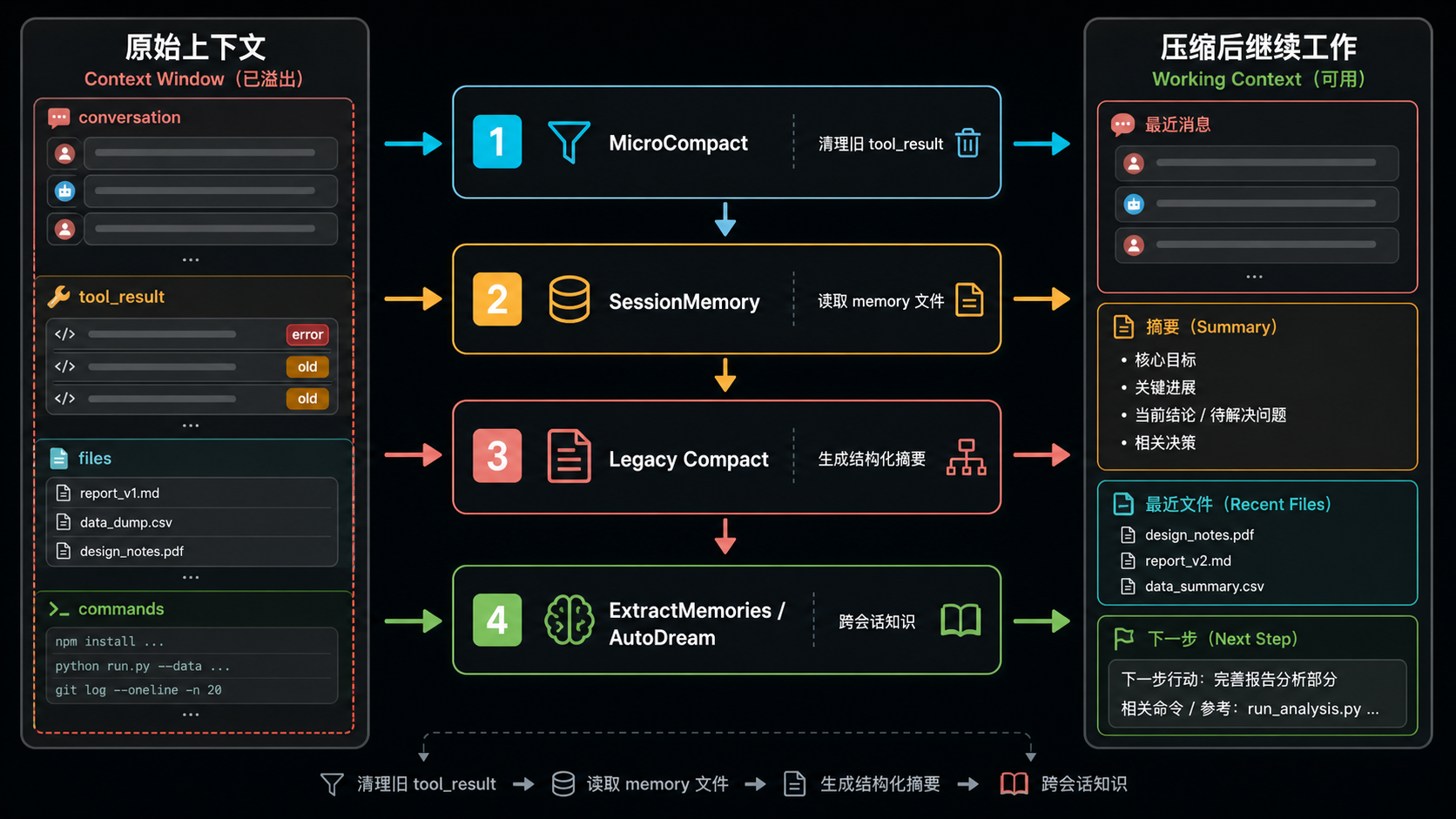
一个心智模型:
前两层是”清空冰箱”,第三层是”切碎打包”,第四层是”写菜谱”。
- 冰箱(上下文)满了之前,先把过期的剩菜(旧 tool_result)扔掉 → MicroCompact
- 还是满,看看有没有现成的备忘录可以代替原食材 → SessionMemory
- 真没办法,请模型重新整理一份精华摘要 → Legacy Compact
- 整个过程中,后台一直有人在写菜谱,方便下次直接用 → ExtractMemories
下面挨个拆。
二、阈值:要在窗口边上留一道安全气垫
很多人的第一反应是「上下文窗口的 80% 触发压缩」。Claude Code 不是这么算的:
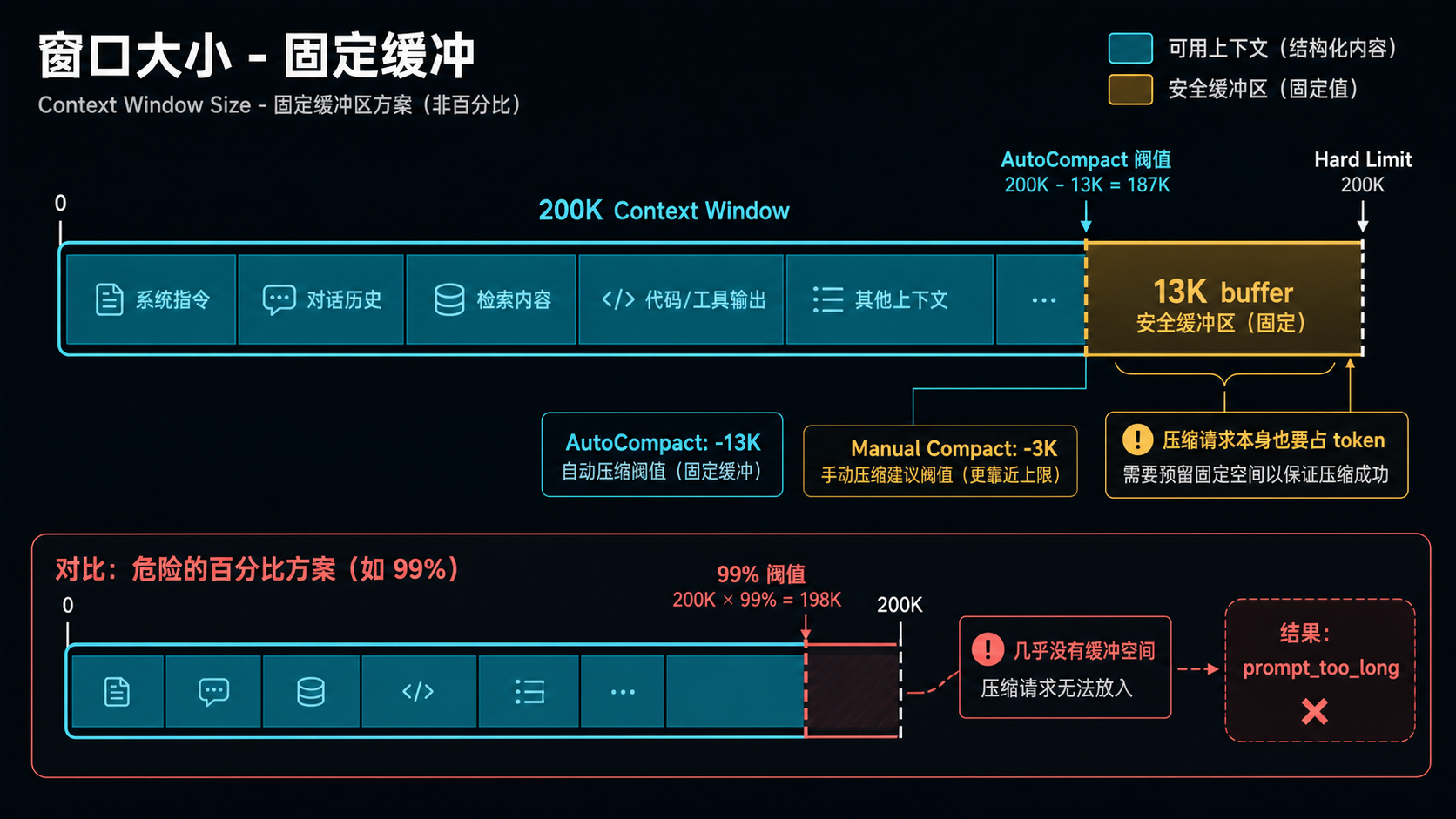
// src/services/compact/autoCompact.ts
const AUTOCOMPACT_BUFFER_TOKENS = 13_000
const MANUAL_COMPACT_BUFFER_TOKENS = 3_000
export function getAutoCompactThreshold(model: string): number {
return getEffectiveContextWindowSize(model) - AUTOCOMPACT_BUFFER_TOKENS
}阈值是 窗口大小减去固定缓冲,自动压缩留 13K,手动留 3K。
为什么要留这么多? 因为压缩本身是一次 API 调用,要把所有历史 + 一段压缩 prompt 一起塞进去。如果阈值卡在 99%,压缩请求自己就会爆。
留 13K 让压缩调用本身不会失败,这是个看似很傻但非常关键的设计。
三、Token 估算:两档够用,不要每次都问 API
调 count_tokens API 是要花钱的。Claude Code 的策略是分快慢两档:
快档:本地估算
// src/services/tokenEstimation.ts
export function roughTokenCountEstimation(
content: string,
bytesPerToken: number = 4, // JSON 用 2,普通文本用 4
): number {
return Math.round(content.length / bytesPerToken)
}length / 4 就完事了。日常每一步的「我现在多少 token 了?」都走这条路,O(1) 无成本。图像/文档固定按 2000 估算,避免低估。
慢档:Haiku 校验
只在「真要压缩了」之前调一次:
const model = containsThinking
? getDefaultSonnetModel()
: getSmallFastModel() // 默认走 Haiku,便宜注意一个细节:不用 Opus 也不用主模型,用最便宜的 Haiku 来数 token。token 数和模型能力没关系,能算就行。
四、MicroCompact:先清掉那些一眼就该扔的东西
大多数 agent 的上下文不是被对话撑爆的,是被 tool_result 撑爆的。一次 read 文件 5K token,跑 10 次就是 50K,但其中绝大多数 90% 的旧文件内容根本没人再看了。
MicroCompact 就专治这个:
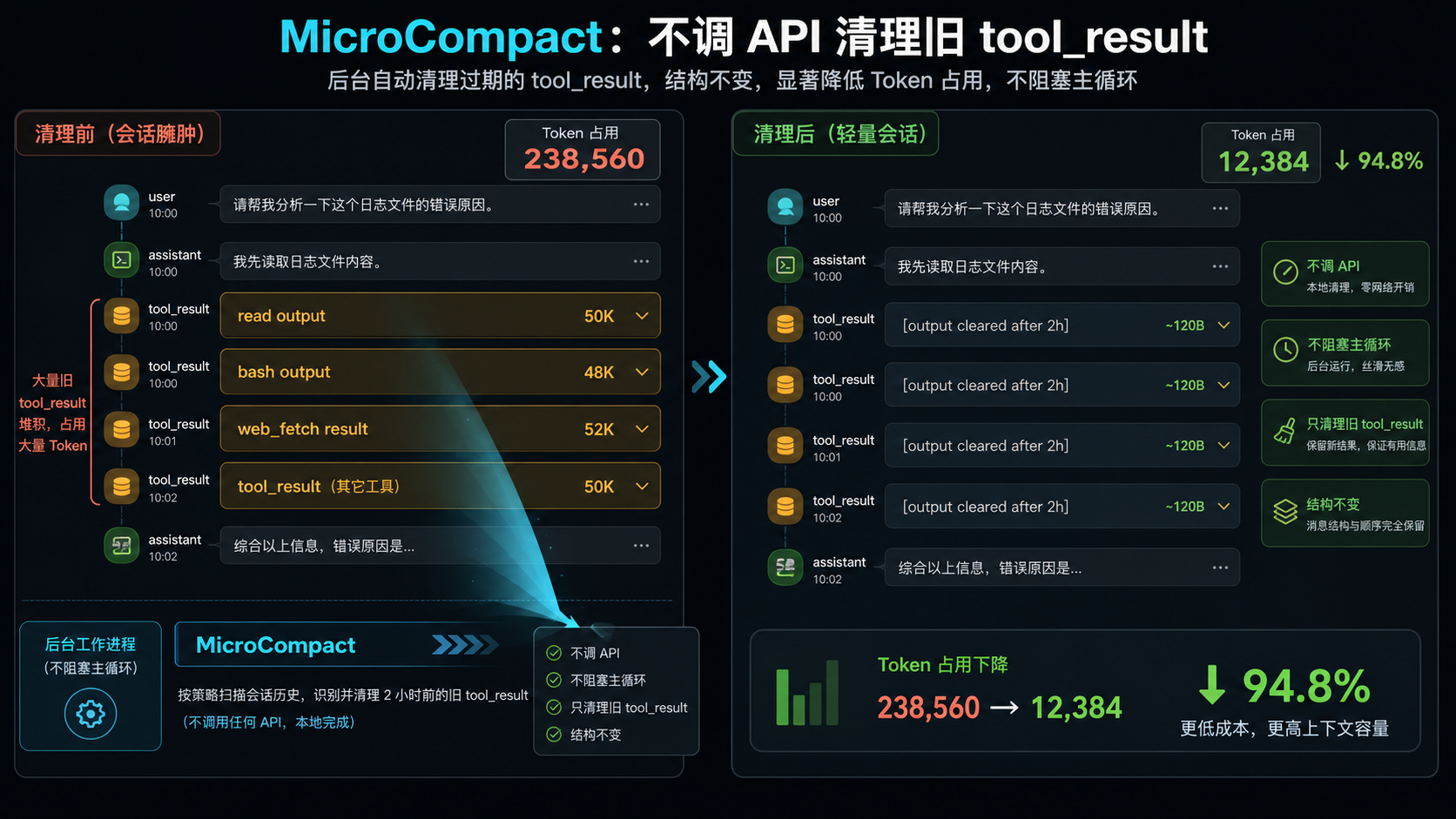
// src/services/compact/microCompact.ts
const COMPACTABLE_TOOLS = new Set([
'read', 'bash', 'npm', 'bun',
'grep', 'glob', 'web_search', 'web_fetch', 'edit', 'write',
])只有这些”产出大块数据”的工具结果会被清理。逻辑很直接:
- 超过 N 小时的 tool_result,整块替换成一行占位符(“[output cleared after 2h]”)
- 不重写消息结构、不调 API、纯本地操作
- 在主循环后台异步跑,不阻塞用户
这是收益最高、最容易抄的一层。如果你只能做一件事,做这个。
五、SessionMemory:让”压缩”变成读文件
这是 Claude Code 比较新、也比较聪明的一层。
设想一下:如果在用户聊天的过程中,有个后台进程一直在记笔记,把”用户问了什么、改了哪些文件、做了什么决策”写成 markdown 存到磁盘上。那么真要压缩的时候,根本不用再让模型生成摘要——直接读那份笔记就行了。
这就是 SessionMemory:
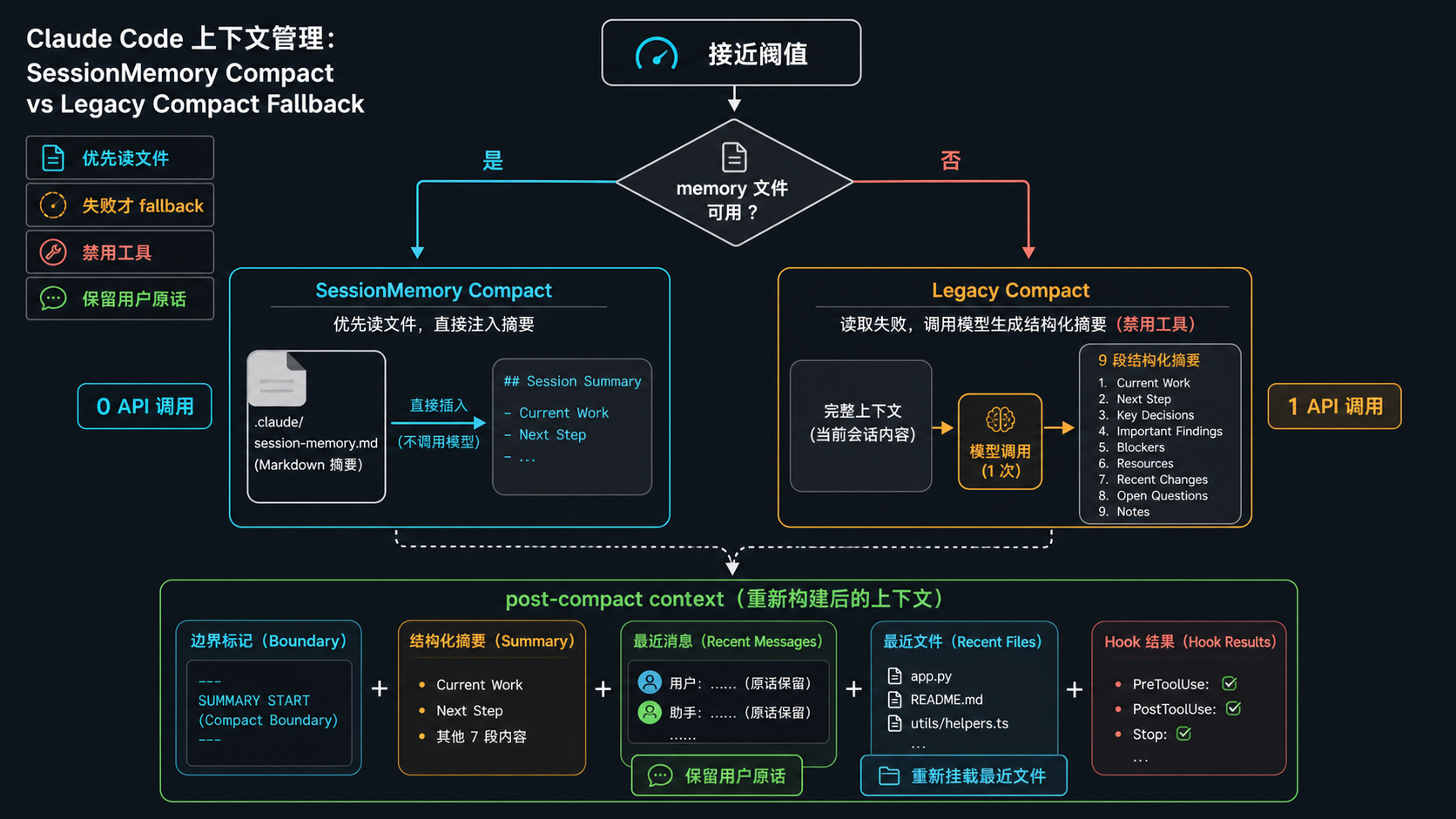
~/.claude/projects/<project-path>/memory/
└── *.md ← 后台 forked agent 持续写入压缩流程:
// src/services/compact/sessionMemoryCompact.ts
async function trySessionMemoryCompaction(...) {
const smContent = getSessionMemoryContent() // 读文件
if (isSessionMemoryEmpty(smContent)) return null // 没笔记,跳过
const messagesToKeep = selectMessagesThatWillFit(messages, maxTokens)
return {
boundaryMarker, // 一个分界符
summaryMessages: [createUserMessage({ // 笔记内容当摘要
content: smContent
})],
messagesToKeep, // 最近 5+ 条原始消息保留
}
}0 API 调用,纯文件读取。如果 SessionMemory 是空的(比如刚开始用),这条路直接返回 null,回落到下一层。
这层的精髓不在压缩本身,而在 “压缩”这件事在后台已经做完了——临到用时只是搬运。
六、Legacy Compact:最后一道防线,把 prompt 写到位
兜底方案。这里最值得抄的是 prompt 设计:
第一招:强制纯文本
CRITICAL: Respond with TEXT ONLY. Do NOT call any tools.
Tool calls will be REJECTED and will waste your only turn — you will fail.压缩是一次性任务,不需要工具。明确禁掉能省一次循环,也防止模型一时手痒去 read 文件。
第二招:要求 9 段式结构化输出
- Primary Request and Intent(用户最初想干什么)
- Key Technical Concepts
- Files and Code Sections(保留完整代码片段)
- Errors and fixes
- Problem Solving
- All user messages(关键——所有用户消息原文)
- Pending Tasks
- Current Work(最近正在做的事,要求详细)
- Optional Next Step(必须 directly aligned with 用户最后一条消息)
第 6、8、9 段是防止压缩后”忘了用户在干嘛”的核心。很多人的压缩之所以让 agent 变傻,就是因为只总结了”做过什么”,没强调”用户最近一句话说了什么、下一步要做什么”。
第三招:压不下就砍最旧的用户消息重试
while (ptlAttempts < MAX_COMPACT_STREAMING_RETRIES) {
try {
summaryResponse = await queryModelWithStreaming(...)
break
} catch (error) {
if (PROMPT_TOO_LONG) {
messagesToSummarize = stripOldestUserMessages(messagesToSummarize)
ptlAttempts++
}
}
}压缩 prompt 自己爆了?砍掉最早的用户消息,再试。最多 N 次。
第四招:压缩后重新挂载文件
// src/services/compact/compact.ts
export function buildPostCompactMessages(result: CompactionResult): Message[] {
return [
result.boundaryMarker,
...result.summaryMessages,
...(result.messagesToKeep ?? []),
...result.attachments, // ← 最近 5 个文件的真实内容重新挂载
...result.hookResults,
]
}摘要里写”修改了 src/foo.ts”是没用的,模型继续编辑还是得知道现在文件长什么样。所以压缩后会重新读取最近 5 个文件挂到上下文里。
七、断路器:别让失败循环烧钱
最后一个小细节,但很重要:
// 同一会话连续失败 3 次后,停止自动压缩API 偶尔会抽风。如果不加保护,压缩失败 → 上下文继续涨 → 又触发压缩 → 又失败……一晚上能烧掉一个月的额度。
Claude Code 给每个会话一个断路器,连续失败 3 次就放弃自动压缩,让用户手动介入。
八、抄作业指南
如果你的 agent 正在被上下文长度折磨,按这个顺序做:
-
先做 MicroCompact:识别 tool_result,按时间或大小清理。不用调 API,一天能写完,立刻见效。
-
本地 token 估算:
length / 4就够日常判断了,别每步都问 API。 -
阈值留缓冲:窗口大小减 10K-15K,不是减 1K。
-
再做 Legacy Compact:
- 单轮调用,禁用工具
- 9 段式结构化 prompt,重点保留用户原话 + 当前任务 + 下一步
- 失败时砍最旧用户消息重试
- 压缩后重新挂载最近文件
-
后台抽 memory:用一个 forked agent 异步写摘要到磁盘,下次压缩直接读。这是从”压缩”升级到”备忘录”的关键。
-
加断路器:连续失败 N 次就停。
结语
Claude Code 的上下文管理之所以好用,不是因为它有什么黑魔法压缩算法,而是因为它把”压缩”这件事拆成了多层时间尺度上的协同:
- 毫秒级:本地 token 估算
- 秒级:MicroCompact 清旧数据
- 当前会话内:SessionMemory / Legacy Compact
- 跨会话:ExtractMemories / AutoDream
每一层都很简单,叠在一起就成了一个稳定的系统。
做 agent 真正难的从来不是单点的”压缩算法”,而是什么时候压、压什么、压完之后让模型还能接着干活。
源码就在 src/services/compact/ 下面,2000 多行,值得读。